


Autonomous AI Agents: Origins (1986-2022)
Part 3 of 4 of Building Blocks for AI Assistants

Voiceover narrated by Ken Herron

Image generated in Adobe Express
This is the third blog post in my Building Blocks for AI Assistants series –
Part I - Knowledge Graphs (2020)
Part II - Dialog Systems (coming soon)
Part III - Autonomous AI Agents: Origins (1986-2022) (this post)
Part IV - Autonomous AI Agents: 2023 and Beyond (coming soon)
While this post describes a different building block of the AI Assistants, it will cover some of the topics already discussed in the series, like Microsoft WinFS or Microsoft Semantic Engine, but from the Autonomous AI Agents' perspective.
What do AI assistants and Autonomous AI Agents have in common? While some members of the tech hype community might think that Autonomous AI Agents made today with the help of LLMs like ChatGPT are something entirely new, they're not, and in my opinion, Autonomous AI Agents should be seen more as a building block of the bigger thing, AI Assistant, then something independent. Why?
To answer this question, let me start with a short overview of what Autonomous AI Agents are, and their origins.
Autonomous AI Agents: Origins (1986-2022)
1986: Society of Mind
In 1986, seminal AI scientist Marvin Minsky published a groundbreaking book “Society of Mind” that provided a fascinating perspective on human cognition. In his book, Minsky constructed a model of human intelligence step by step from the interactions of simple parts called agents. These agents are “mindless”, yet their interactions constitute what Minsky terms a “society of mind”. The central idea is that the human mind, and any other naturally evolved cognitive system, is a vast society of individually simple processes (agents). They can be seen as a typical component of a computer program and can be connected and composed into larger systems (societies of agents) that perform functions more complex than any single agent could achieve alone.
While Minsky’s book doesn’t explicitly focus on “autonomous AI agents”, its exploration of the mind as a society of diverse agents capable of talking to each other and working cooperatively in solving complex problems contributed to humanity’s understanding of cognition and artificial intelligence.
1991: Autonomous AI Agents
The concept of autonomous AI agents has been explored in various disciplines, including cognitive science, ethics, and social simulations. However, its origins trace back to economics, where a "rational agent" was defined as anything with a goal. In 1991, Brustoloni characterized autonomous AI agents as systems capable of autonomous, purposeful action in the real world. In 1995, Maes described them as computational systems inhabiting complex dynamic environments, sensing and acting autonomously within those environments to achieve specific goals or tasks. In 1997, Franklin and Graesser proposed their definition: "An autonomous agent is a system situated within an environment, sensing and acting over time in pursuit of its agenda."
1998: Autonomous AI Agents and Multi-Agent Systems
Coming back to the development of the human psyche, which facilitated social bonding and cooperation, the idea that multiple autonomous AI agents could work together, cooperatively, became a second source of inspiration. By working together, early humans could tackle larger challenges, from hunting to defending against predators. In humanity, social structures and norms evolved as part of this cooperative effort, further enhancing survival chances. By adding an element of cooperation to the concept of multiple agents combined to address complex problems they couldn’t address individually, the idea of multi-agents was conceived.
In 1998, an Autonomous AI Agents and Multi-Agent Systems journal was officially created by the International Foundation for Autonomous AI Agents and Multi-Agent Systems. Following was a lot of excitement in the computer software industry and academia alike; the concept of the systems capable of subscribing to the incoming information about the ever-changing environment and autonomously performing actions, individually or cooperatively, inspired students and software engineers worldwide.
2001-2006: Information Agents amp; WinFS in Windows Codename Longhorn
One of the first steps towards bringing Autonomous AI Agents into the mainstream product was taken by Microsoft in 2001 while building the next version of the Windows operating system, codename Longhorn. One of its key new features was WinFS, or Windows Future Storage, also known as Windows File System. Before WinFS, all client applications were designed in the following fashion, from the information architecture perspective:

WinFS was designed to rethink the File System Layer as a more intelligent OS's storage subsystem. The goal was to enable Windows applications to store their information, be that structured (e.g., XML), semi-structured (e.g., Word document), or unstructured (e.g., raw image) in the same data environment, also known as Integrated Storage:

To enable these storage scenarios, WinFS was designed as a combination of two layers (following the logic used in this post):
Unstructured Data Layer that worked on top of SQL Server and NTFS
Common Structured Data Layer that worked on top of SQL Server
This means that all data was stored in NTFS while unstructured data lived in NTFS directly (images, videos, etc.), structured data was represented as a combination of tables in SQL Server. Semi-structured data was layered on top of tables in SQL Server and NTFS. While WinFS as a project was canceled, this technology was shipped as part of a later version of SQL Server, culminating in FileTables in SQL Server 2012.
WinFS.exe was a custom version of sqlserver.exe, so, WinFS was a fork of SQL Server 2000 and was developed in parallel with SQL Server 2005 (codename Yukon).
Yet storing information inside WinFS was just a necessary step towards what was called Information Agents. Here’s an excerpt from a Seattle Post-Intelligencer Reporter (2003) article:
The new operating system will also be able to run what the company calls information agents. These programs take advantage of the Longhorn file system's structure to let users set up their computers to respond in specific ways to various types of incoming information.
“Think of it as in-box rules on steroids,” Microsoft executive Gordon Mangione said, referencing automatically directing incoming e-mail messages to particular folders based on content or origin.
In the hypothetical situation demonstrated yesterday, one such information agent was programmed to check the caller ID on incoming calls, match that phone number to a law firm's client database, and determine whether the caller's case involved a settlement amount of US$2 million or more. In the scenario, the caller met the criteria, so the program checked the lawyer's schedule and responded in a computerized voice while the person was still on the line.
“Hi, Jeff, I am unavailable at this time, but I will call you back at 2 p.m. when I get out of my meeting,” the voice said.
Below is a screenshot of a prototype of the Rules and Alerts user experience, part of Windows Longhorn that was built on top of the Information Agents technology:
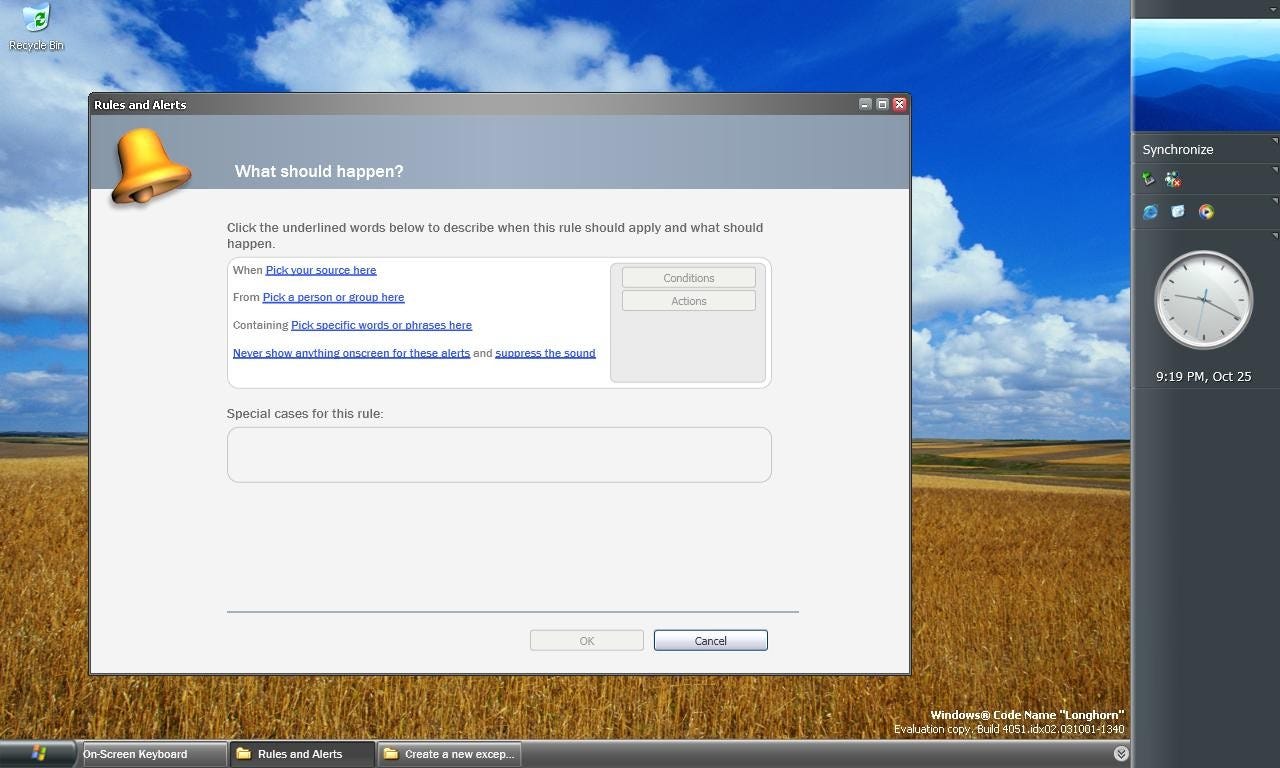
This user interface looked quite rudimentary compared to the broader Information Agents vision, and was, indeed, inspired by the Rules and Alerts user interface in Microsoft Office Outlook. However, if implemented in full, it would enable users to get their Information Agents up and running on their computers in the mid-2000s.
To enable Information Agents, WinFS introduced the concept of the Item Definition Model, or IDM, where each object in the real world would have its own structured or semi-structured representation in the object-relational form inside WinFS, with its programming type (as in C, C++, C#, or Java etc) corresponding to its philosophical type.
The initial IDM model, also known as Windows Types, or WinFS Schemas, incorporated high-level concepts, like Documents, Music, Video, and Picture, and other concepts like Person, Group, and Organization. The key power of WinFS was that each such concept would have an extensible schema of properties of various types as well as relationships defining connections between instances of these concepts. So, for example, a person named “Bill Gates” would have a relationship with AuthorOf for a recorded video called “Information At Your Fingertips”, and another relationship with an organization called “Microsoft Corporation” (see Third-party overview of IDM).
The goal of WinFS was that data coming from different applications would be represented via its extensible IDM, connecting individual items representing the same real-world objects across multiple applications (e.g., contacts from Outlook and CRM). This means that applications had to be rewritten: no longer being isolated silos, applications now we're expected to rebase their application information architecture on top of the common structured data layer of WinFS, IDM, extending it with application-specific extensions
Essentially, WinFS was an extensible personal knowledge graph, designed to be semi-automatically populated by the participating applications, making each real-world object a first-class citizen inside WinFS.
Although the final version of WinFS has never been shipped, the Beta version was released in 2005, inspiring enthusiasts globally to envision new products based on it.
2003-2022: Microsoft Semantic Engine, Zet Universe, Palantir, RPA and Application Integration Platforms: Semantic Processing Pipelines, Context Processors, and Dynamic Ontologies
WinFS was one of several projects towards the Integrated Storage vision of Bill Gates; as such, its team in the very beginning (2001) was choosing between being a place where all OS and applications data is stored or a place where a representation of the OS and applications data is stored. In other words, the choice was between Storage and Search Index.
WinFS team chose Storage.
By choosing Storage, the WinFS team expected that each application would essentially give up ownership of the application data, sharing it with other apps and the operating system itself:
WinFS was canceled, and, probably, one of the reasons was that Information Agents were cut from Windows Longhorn. Without them, there were not many incentives for application developers to give up their application data to the operating system or to share it with other applications. There was also an option for the applications to store their application data in existing proprietary formats using Win32 File System APIs (as a compatibility layer), of course, but using that approach would not enable any new scenarios WinFS was designed to facilitate.
A new generation of projects after WinFS chose the second option: Search Index.
Windows Explorer in Windows Vista While early versions of WinFS used built-in full-text search from SQL Server, in the latest versions of WinFS (Summer 2006), it was redesigned to use external search indexing tech, Windows Search. By that time, Windows Search became a new component of the operating system in Windows Vista. Being a rebranded and rebuilt version of earlier MSN Desktop Search, Windows Search provided a centralized Search Index for all client applications running on Windows Vista:

Like WinFS, it provided an Item Definition Model called Windows Property System. Windows Search indexed all fixed disk drives and used plugin architecture to index application stores. While Microsoft used Windows Search to index its application stores, like Microsoft Office Outlook, Microsoft Office OneNote, etc., Windows Search was designed to be extensible by third-party applications, too.
However, applications were not required to use Windows Search as a mechanism for a centralized search index, and Windows Search never enabled the Integrated Storage vision of Bill Gates (not that it was expected of it).
Microsoft Semantic Engine, née Arena Information Agents in WinFS and Windows Longhorn were designed to observe changes in the incoming information and do actions pre-programmed by their users, essentially making them a functionality enabling both the so-called prosumers (professional consumers) and corporate users at a personal scale. While the WinFS project was canceled in the summer of 2006, one more Integrated Storage project started at Microsoft in 2007, née Arena, also known as Microsoft Semantic Engine (see PDC 2009 Microsoft Semantic Engine talk).
Unlike WinFS, Arena eventually morphed into a Search Index instead of Storage, though one might argue it was a mix of both approaches: Storage/Search Index. Why?
As more and more end-user and world information was published uniquely on the Internet, it became clear that the Integrated Storage vision could be better implemented as a representation of the user and world knowledge rather than a storage of user and world knowledge

Ahead of its time, Arena incorporated the feedback the company learned from WinFS, and addressed one of the key limitations of WinFS, decoupling the representation of the philosophical type from the programming type. So, every item in Arena would have a property called Kind representing its philosophical type, like Document or Person, but the programming type would remain the same: item. In Arena, data would also come from external data sources via plugins, and be created inside it by the user and applications. This decoupling introduced an independent hierarchy of types, or kind, forming the so-called ontology. This ontology, like in WinFS, could be easily extended by its plugins, but also by the users themselves.
And like in WinFS, Arena had a core concept of plugins that would process incoming information and further organize it, manually or automatically, essentially becoming semi-autonomous AI agents. Unlike WinFS, however, Arena had a more familiar to today’s data scientists semantic processing pipeline for sequential data processing its plugins:

Plugins could participate in different steps: they could connect Arena to external data sources (e.g., Bing, Microsoft Exchange, Facebook, etc.), classify incoming information, extract properties and relationships (hence linking incoming data with existing data), and then send data towards indexing into Arena storage/index. But, most importantly, plugins could subscribe to any change of any data item (kind) and perform actions over that data item, essentially enabling the "Information Agents" vision rooted in WinFS.
Zet Universe
Unfortunately, Arena only got a chance to be presented at Microsoft PDC 2009 and was never given to the public. Its ideas, as well as ideas of WinFS and concepts of post-desktop Digital Work Environments, continued to live in my first company, Zet Universe, Inc., a startup I started in 2012. Zet Universe was inspired by several ongoing research projects in Human-Computer Interaction focused on building Digital Work Environments designed to replace aging desktop metaphors in modern devices that incorporate other input forms, like multi-touch or pen, and air gestures. Like in Arena, Zet Universe had a concept of ontology decoupled from the data types so that programming representation of real-world objects would be done via Entities, Properties, and Relationships between them.
Like in both WinFS and Arena, Zet Universe had a concept of plugins, called Apps connecting external data sources into it, and plugins called Processors, focused on sequential information processing. Essentially, these plugins could extract metadata from the incoming data into Entities, Properties, and Relationships, in either manual or automatic mode. And like in WinFS, Zet Universe had a concept of rules that users could define to introduce custom information processing logic, e.g., “if entity kind is email or instant message and its author is your direct manager, mark it as important.”
Unlike WinFS and Arena, however, Zet Universe was initially designed as a Digital Work Environment, so it provided an end-user experience that visually organized all user information into a set of projects, with each project configured to absorb and process incoming information from external data sources based on user expectations.

However, for personal reasons, I shelved Zet Universe in 2017 and only revived it in the 2022-2023 timeframe; inspired by the new functionality enabled by the wave of LLMs.
Palantir Gotham
The same approach of semantic processing pipelines and extensible ontology was successfully applied at a bigger scale at Palantir in the Palantir Gotham product. Similar pipelines for data processing, similar plugins for incoming information, and data processing, a similar concept of ontology that could be further extended – they called it Dynamic Ontology. From a technical perspective, Palantir Gotham was designed as a client-server solution, and, in a way, resembled both Arena and Zet Universe:
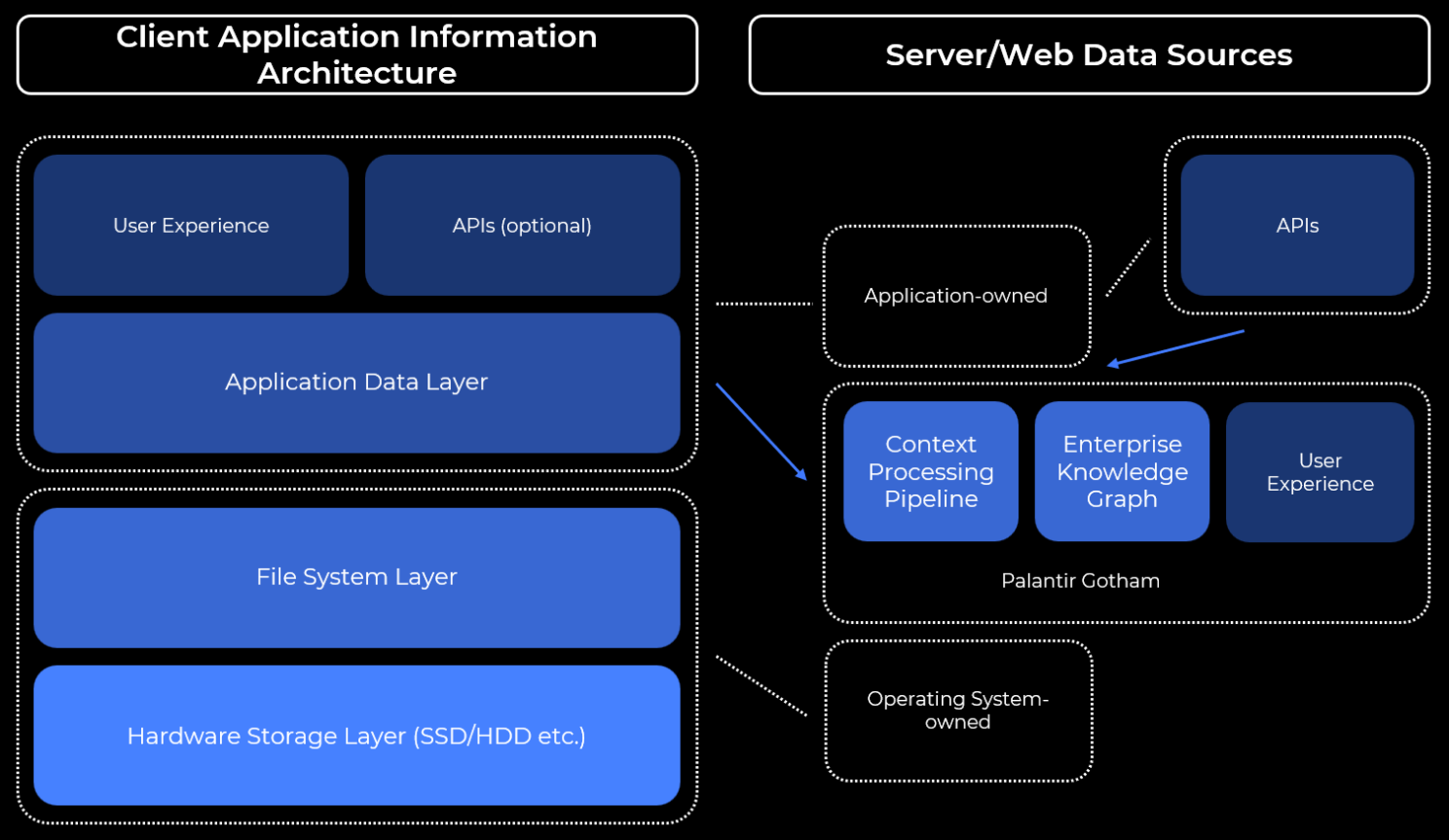
The combination of the Palantir Gotham software with trained analysts enabled governments and the private sector to extract the value from the custom knowledge graphs organized in the software for addressing various user needs, such as research analysis or business intelligence tasks. Yet the need for trained analysts and the complex setup required to make Palantir Gotham work at the deployment locations made the cost of the complete solution too high for this approach to be used at a bigger scale.
RPA & Application Integration Platforms
A yet another approach to software agents capable of automatic data processing was introduced by a wave of two different integration technologies: application integration platforms (e.g., Zapier and IFTTT) and Robotic Process Automation (RPA, e.g., UiPath and Automation Anywhere).
Application Integration Platforms, like IFTTT (if-this-then-that), brought back the idea of WinFS’ Information Agents, or autonomous AI agents, through an idea of small programs with its logic described in the form of conditions and calls to APIs of the applications connected to these platforms:

Essentially, Application Integration Platforms introduced a combination of a Semantic Processing Pipeline that incorporated data from 3rd party applications, a Rules Engine that executed on top of the incoming data, and a variant of a Search Index that tapped information about incoming data and rules.
So, the original scenario from the Information Agents article, “information agent was programmed to check the caller ID on incoming calls, match that phone number to a law firm's client database, and determine whether the caller's case involved a settlement amount of US$2 million or more”, could be easily implemented in these systems as long as they had programmatic access to the APIs of the participating applications, like phone calls on the phone, CRM database, employee database, and corporate calendars of the employees. Here's a simplified representation of the IFTTT logic:
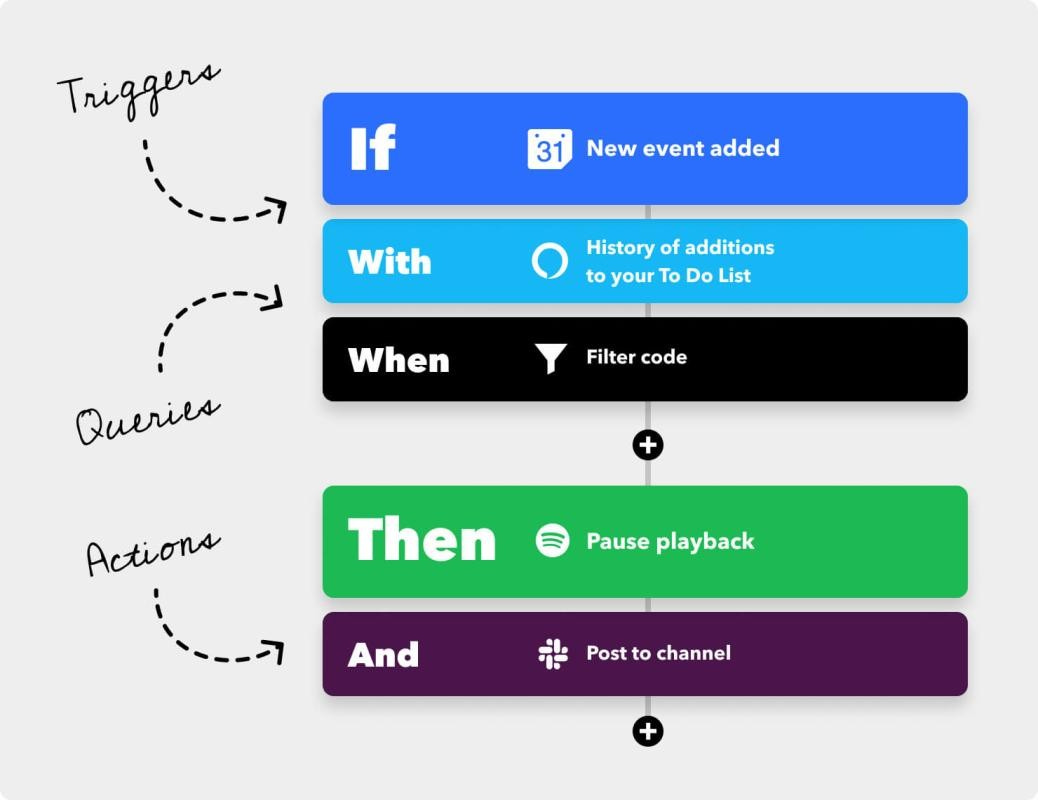
However, if these APIs were not unavailable, or didn’t support the desired scenarios, these application integration systems couldn’t help their users in addressing their needs.
This is where RPA solutions stepped in: instead of requiring access to the APIs of the applications to control, RPA-based systems introduced a concept of components capable of interacting with the live desktop, web, and even mobile applications by imitating end-user behavior by clicking on the interactive elements like buttons, links, etc., entering text into the text boxes, etc.
However, to enable these scenarios, RPA systems returned to the client side:
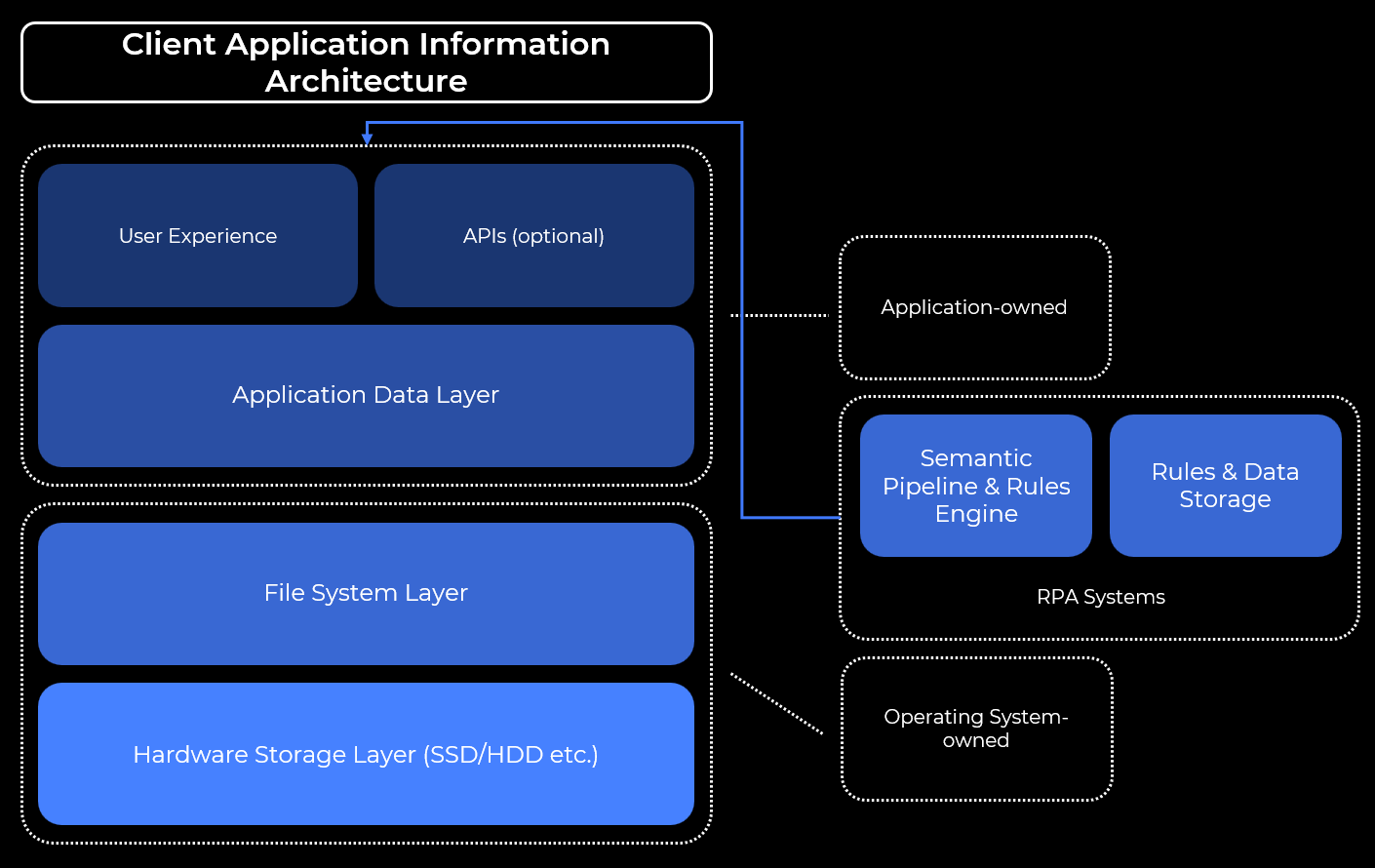
Essentially, RPA systems allow their users to create workflows for repeatable, never or rarely-changing tasks, like taking notes from the meeting a user had with their customer, then saving them to the CRM system, saving users time from manually bringing these notes into the CRM. However, like in the case of the Application Integration Platforms, RPA solutions were also limited. These solutions would only work with the pre-determined and never-changing versions of the corporate applications, and any change in these applications or the process would bring automation enabled by RPA to a halt.
Finally, some of the RPA systems were combined with the Application Integration Systems into hybrid systems like Microsoft Power Automate, uniting the ability to control client (native and web) applications through UI Automation with the ability to interact with application APIs (server and web-based):

Autonomous AI Agents in 2022: Proved Success
As evident from this post, the idea of Autonomous AI Agents goes back to 1986 with Marvin Minsky's Society of Mind, though the term was formally introduced in the early 1990s. One of the first software implementations called Information Agents was designed to be shipped as part of WinFS and Windows Codename Longhorn in the mid-2000s. While that vision was too ambitious and was scaled back, over the years multiple companies successfully used a combination of Semantic/Context Processing Pipelines, Knowledge Graphs, and Rule Engines to implement some form of Autonomous AI Agents in their business scenarios.
This is supported by market data –
Palantir's market capitalization as of 3/31/2024 is estimated at US$50.89B.
The global application integration market size was valued at US15.4B in 2023 and is projected to grow to US$38.4B by 2028, representing a Compound Annual Growth Rate (CAGR) of 20.0% during the forecast period (MarketsandMarkets).
The global robotic process automation market size was valued at USD 18.41 billion in 2023 and is expected to reach US$178.55B by 2033, anticipated to grow at a noteworthy CAGR of 25.7% over the forecast period 2024 to 2033 (Precedence Research).
Note: Certainly, Palantir Gotham and newer systems go way beyond a Rules Engine, providing highly customized user experiences supporting a variety of business and public sector scenarios.
Autonomous AI Agents in 2023 and Beyond
With that said the next wave of Autonomous AI Agents started in early 2023, following the explosive growth of ChatGPT and its broad availability via OpenAI's APIs. I'll write a separate post about this new wave, but for the time being, let me share a quick thought on the key difference between RPA systems with Application Integration platforms and this new wave of Autonomous AI Agents:
“The value of autonomous AI agents that control apps, in comparison to classic RPA and application integration platforms like Zapier, lies in the ability of agents to design a plan for solving a problem on the fly, as well as to figure out how to get things done while interacting with apps they've never seen before.”
Stay tuned for the next post in the series!
I first published this article on LinkedIn.
 | A guest post by
|
To provide another perspective, I wrote an article about chatbots and AI agents because I noticed that for a long time (past 5 years) chatbots failed to meet expectations due to their inability to handle the complexity of human conversations.
This transition from “chatbots” to “AI Agents”can partly be seen as a rebranding effort, aimed at distancing these advanced systems from the shortcomings associated with their predecessors. But it also marks a pivotal moment. We are witnessing a departure of sorts, a generation of chatbots (and the frustration that came with them) is dying and replaced with something new (and hopefully better).
https://jurgengravestein.substack.com/p/goodbye-chatbots-hello-ai-agents